Motivating The Case for Decentralized Social Identity: Part One
E. Glen Weyl, Lucas Geiger, Kaliya Young (Identity Woman)
June 6, 2019
Just like cameras do violence to the richness of sight, today’s identity systems do great violence to the richness of who we are, something we are reminded of and annoyed by every time we use them. Consider:
- To authenticate you, most identity systems today rely on an elaborate key or password that most people cannot remember, and which has no personal significance to them.
Most sign-up systems on the internet ask you to use one of a small number of digital identity providers, such as Facebook, Google to login in with. Some requiring “proof of ID” may also ask you to scan in your government issued identity documents. Such systems reduce you to an appendage of these leviathans and leave your identity vulnerable to theft by anyone who obtains your associated credentials. - At the same time, such identity systems have a severely limited range of application; they do not enable you to prove to others most of the attributes of your identity that, in usual human interactions, would be relevant or that we would use to describe acquaintances. Facebook single sign-in does not allow you to prove you are an observant Muslim, an accomplished artist, a loving partner, a well-trained markswoman or a volunteer firefighter. Assertions of such attributes are common on personal webpages, but verifying them is something that, while relatively easy in standard social networks in real life (IRL), is challenging or sometimes impossible online.
- In the most extreme case of the digital world reshaping our lives in its own distorted image, we are increasingly asked to make a stark choice between a complete anonymity that fosters extreme irresponsibility and identification that exposes much of our lives to anyone we identify ourselves to. Where once individuals rotated between a variety of contexts (e.g. social, religious, professional, etc.) and verifiably shared aspects of themselves in each of these settings, increasingly information is either public and open to all or private and tightly concealed.
How can we escape this nightmarish oversimplification that technology foists upon us? Retreating from technology is not a viable option, as so much of our lives now depend on the elaborate information systems we have built. But as the rise of virtual reality systems have shown, building technologies that more completely represent our lived experiences is possible, at least gradually. By investing in such systems, we can continue to enable technological advance and simultaneously reduce the impoverishment of our self-imagination they are currently causing.
In this series of posts we aim to describe some of the fundamental features that such a system would need and what such a system, if successful, could enable. In doing so we seek to motivate both general work on solving this problem, as well as teeing up a follow-up post in which we will describe a recently-released proposal for addressing these problems, as well as prospects for its implementation.
To avoid the worst pitfalls of existing identity systems, we believe any successful system must be humanistic, flexible, decentralized, and social. It must be humanistic in the sense that it allows individuals to prove their unique humanity without requiring them to behave like machines. It must be flexible in the sense that it allows individuals to present a wide range of subsets of their identifying information in different context, as appropriate and required, without immediately implying the present the rest of their information alongside this. It must be decentralized in that most identifying information should not be stored by and most protocols for validating such information should not flow through a small number of data hubs. Finally, it must be social in that it recognizes that nearly all data of any value is shared across individuals and that it is the pattern of sharing rather than failures of perfect privacy that must be properly managed.
An identity system capable of achieving these properties would not just avoid the flattening of our self-conceptions; it would also open up astonishing new possibilities for social organization that the internet has thus far failed to support. It might be as big an advance over the existing structure of the internet as it was beyond previous technologies. This post focuses on the requirements for such a system to achieve its potential.
The following two posts follow up by discussing (in the second post) some very concrete, near-term improvements such a system could deliver and (in the third post) how it could more broadly transform the foundations of our democracy and economy. The second post focuses on remedies that decentralized identity have to the current state of the art: how to provide user control, access to justifiable parties, and other “laws of identity”. It also highlights opportunities that decentralized identity systems create which historically were not possible. For example: resolving the tension between privacy and voting exploits in online communities and governance mechanisms in Decentralized Autonomous Organizations. We explore the case where abundance of privacy can be coupled with abundance of profit. The third post imagines transformative of such an identity system for political economy. It explores how it would enable much more flexible and responsive democracy at a global scale than has ever been possible, how it could empower a new data economy based on collective organization to reclaim data value from corporate platforms and how, most radically, it could eventually lead to the replacement of money by a new, more social and system of value aggregation.
Together these three posts are long, and readers may be interested in different parts. Those focused on identity solutions per se will be most interested in the present post. Those focused on near-term entrepreneurial applications will want to focus on the second post. Those most focused on broad social and political economic implications may wish to turn to the third post.
Humanistic
One of the most sought-out capabilities of an identity system is the ability to prove to a verifier one’s unique humanity, namely that you are the same human being accessing the system over time through a singular account and only having one account on the system. This capability is known in the technical literature as “sybil-resistance”, for reasons not worth elaborating on here. This may strike a reader unfamiliar with the topic as both a bit trivial (how hard can this really be?) and not terribly interesting (how much can this really do?). However, as we will explain, it is actually quite a core feature and while it is separable from other important features of some identity systems it is so fundamental that it determines whether it is capable of formalizing the concept of the unique dignity of each human life. As such, we refer to it here non-technically as “humanism”: that the identity system can formally represent and attest to the unique existence and worth of each human life.
Why is humanism so important? Consider a voting system based on the principle of one-person-one-vote. To have any chance of maintaining the integrity of such a system, you must be able to ensure that no person votes twice. No matter how well such a system operates along other dimensions, if it cannot tell that someone requesting the right to vote has already voted, it will be possible for any participant to vote as many times as she wishes. In such a scenario, the election’s outcome will be the preference of whichever participant is sufficiently unscrupulous and has enough time or resources to vote most frequently, not the will of the majority. Very often, those with the most resources or some other form of power will be able to ask the system most persistently for a vote and thus the absence of humanism will cause democracy to degenerate into plutocracy.
To see why humanism is a distinct feature of an identity system and not equivalent to other functionality, consider two common IRL approaches to proving identity properties, one aimed at ensuring humanism, the other aimed at enabling a participant to prove a property of herself. First, in countries where there is limited civil registration capacity and voter registration is prone to error, to ensure voters only vote once (even if they happen to be on more then one voter list) one technique is to simply dip a particular finger of a participant who has voted in temporarily indelible ink.
This ink wears off within a few days but cannot be washed off or otherwise removed during its active period. This ensures that anyone presenting herself to vote may vote precisely once, as those presenting a marked finger are denied access to the ballot. Note, however, that this system accomplishes nothing else that we usually think of identity systems as doing. It does not even use or require names and is particularly common in areas where unique names are not frequently given.
In contrast, consider a familiar practice that is not humanistic, but which does allow the proof of a property of identity: the use of wristbands to prove eligibility to drink alcohol. While such wristbands are often issued based on an initial inspection of an identification card, they need not be. For example, suppose it was possible to test a property of an individual’s blood which indicates they are of legal drinking age and subsequently issued them a wristband based on this test without learning anything further about their name or background. Once one has such a wristband, it doesn’t show anything about the person’s uniqueness; they may go to the bar as many times as they wish using the wristband. The wristband is trivial to exploit. In fact, it is common to give each participant some number of coupons precisely because the wristband on its own says nothing other than that the participant is authorized to order alcohol and thus in no way helps limit consumption.
So humanism is a critical and distinctive feature, but why is it so hard to achieve? IRL one approach to humanism would be the distinctiveness of human faces or fingerprints. Yet while these may be quite useful in proving that are a particular person (though even there, challenges emerge), they are not terribly useful in proving your distinctness and little else. Without a database of all human faces or fingerprints to compare against, it is actually quite easy to produce a face or fingerprint indistinguishable from human and yet distinct from all other humans, and to do so in volume. This problem is particularly severe on the internet, where such biometrics are impractical to incorporate (and dangerous from NIST security best practices point of view, see: https://pages.nist.gov/800-63-3/sp800-63-3.html) to incorporate, and in any system that you do not wish to prepopulate with every allowable credential (viz. every known face or every known fingerprint). Facebook, for example, in its early days relied upon university run email systems to gain access, assuming no one has more than one such @.edu address. Clearly this was not a scalable or resilient system. The advance of technology seems to be making this problem progressively harder, as techniques for generating unique-seeming features of humans become ever cheaper.
Thus, humanism turns out to be one of the most challenging, important and unique capacities of an identity system. This question of “who are you” arises in all types of contexts related to identity, however, the words “who” and “you” are much more complex than we might at first imagine.
Flexible
First consider the meaning of “who”. We could ask a passerby on the street “who are you” they might respond “I am Mohammad Khan”. This is not very informative at all, because this is the most common name on earth. However if this person were instead to share information about where they were born, their religion, where they were educated, the year they were born, and other such information, we might quite quickly get a sense for such a person. Yet, the precise list of such information could differ greatly from one context to the next, or according to who the requestor is. For example, in one setting you might introduce yourself by describing the sports you played growing up, your favorite music and where you used to vacation. In a healthcare context one might describe the list of all surgeries you have undergone, the set of diseases you are genetically predisposed to and your known allergies. In the context of seeking employment you might describe companies you have worked for, courses completed, and languages spoken.
These perspectives provide richer windows into aspects of your identity than does a name by itself, which after all is simply a description of the family you come from and an arbitrary label assigned to you by your parents. They may even be, together, enough to uniquely identify you. Yet each is separate from the others and (without further references) does not tell you anything about the others.
In the digital world we don’t have tools to help us pull together and anchor a holistic picture of all our identity contexts so we can manage them differently in different contexts and have autonomy, integrity and dignity as a person.
Domains
Many of the issues in reasoning about identity come from the multitude of domains in which we apply labels and permissions attached to individuals. One of our co-authors, Kaliya Young, developed a framework for categorizing the areas our personal information touch databases.
Of the sixteen domains, the first one is “Me and my Identity” where individuals work to collect their own identity information and the individual serves as the source of identity information in all subsequent domains.
The second domain involves delegated relationships where parents manage the identity information of their children and then those children in time as their parents become elders might manage the ID of the parents.
Then next 12 Domains involve four large contexts Government, Civil Society, Commercial, Employment And three different types of interactions: Registration, Transactions, Surveillance. This is a useful framework for classifying different types of interactions with systems that involved the collection of PII.
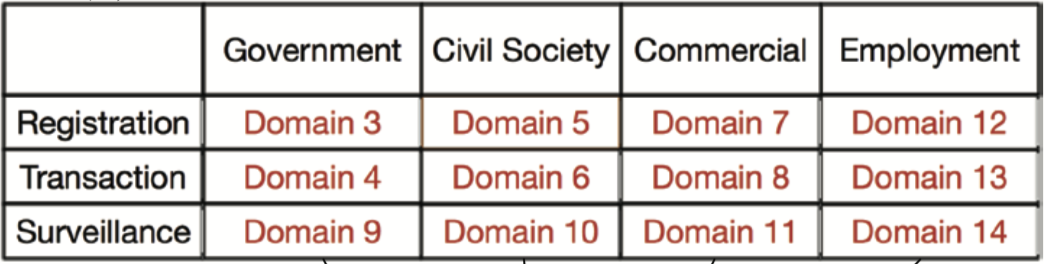
Domain 15 is where Data brokers which have access to government and commercial databases to repackage for resale.
Finally Domain 16 Black market databases from hackers and even nation state actors, who obtain data from databases in all of the above domains unbeknownst to users and platforms.
Mixing attributes from multiple domains and use cases has inevitably led to inadequate and even dangerous implementations. Much of the digital identity work comes from a needs of media and commerce, where tracking of the interactions are paramount, moving similar authorization protocols to government it inadvertently creates an audit trail for every time someone interacts with a system.
As digital identity systems begin to be introduced in government services, some countries have gone ahead with the patterns and practices of centralized digital identity providers on the internet, where systems originally intended for commerce, are being extended to other domains transitively through government, having increasing and material impact on the users.
Take for example India’s national digital identity system, Aadhaar. Initially it was conceptualized to deliver services to the most vulnerable of the population. Today, the techal-political leadership sees this identity system as singular link for all domains of identity for residents of India. The problems are manifest, and non-speculative: people who have difficulty enrolling in the system or once enrolled have difficulty doing authentication are not receiving food rations.
Almost exclusively, the domains described above are institutional in nature. Typical hierarchical architectures (i.e. my identifier belongs to someone else’s namespace), don’t capture the dynamism of our movement through our social spheres. Beyond hierarchical, any fixed association between people misses a larger phenomenon in the social world where our own conceptions of ourselves are not discrete. We are works-in-progress in certain domains, more verb-like (studying at Princeton) rather than noun-like (a student at Princeton).
Getting a single system to be generalizable and cover all cases creates vulnerabilities soon followed by exploits. But it also causes unintended social consequences. In many identity system architectures there is an assumption of a correlation of these fragments to one individual (to create the sybil resistance described above). This forced correlation, flattening of the self, in reality jeopardizes the most vulnerable. We don’t need to travel very far to see scenarios where a person requires two online identities for physical safety: think of journalists covering the drug war in Mexico. Multiple aliases are a necessary survival tool, an all-inclusive identity provider which correlates these identity factors onto one human body, could not credibly guarantee that journalist’s safety in a one-size-fits-all approach.
Social
Next let’s consider “you”.
Most of us tend to think of the information described above as “personal data”, things unique about ourselves as individuals that we would generally like to keep private. Yet, upon reflection, we must realize that nearly all this information is already shared with others and in fact would have little meaning were it now. We played our favorite sports growing up with others; thus, our favorite sports are data already shared with them. All surgeries we have undergone were performed by some surgeon; thus again, each bit of our surgical histories is are already shared at least with those attending that surgery. Courses we took were taken with others and taught by some teacher; companies we worked for have records of our employment there. Even our “mother’s date of birth” is also our mothers’ “date of birth” and our grandmothers’ “date of birth of first child”. That is, there is no such thing as truly “personal” or “private” data; nearly all data is created in the context of social interactions and thus inheres not in single individuals but instead in social groups.
Thus identity is inherently both fragmentary (there is no singular and exhaustive explication of the “who”) and social (“you” are not an island unto yourself, but instead a series of socially-defined positions). One of the great social theorists of these properties of identity, who we will discuss further in our upcoming blog post, was Georg Simmel, a founding figure of sociology at the turn of the 20th century. Simmel argued that we should think of ourselves as being the intersection of the social groups we take part in and that what defines our individuality is that no other individual is part of precisely the same collection of social groups.
While these properties may initially seem unwelcome complications, they in many ways make the identity problem easier. If identity were unitary, there would be no choice other than full anonymity and fully revealing oneself. However, because identity is fragmentary, we can partially identify ourselves in relevant ways in a variety of different contexts. If identity were entirely private, it would be very hard for me to prove things about ourselves without invasive surveillance, as we would need a system to watch us and ensure that the things we say about ourselves are true. However, given that almost all our lives are already shared with others, it may be possible to harness these organic relationships to verify properties about us. Any effective identity system should therefore harness these features and avoid flattening our personalities to either a unitary representation or to a narrow individualism.
Decentralized
Prior to the modern era, identity was primarily based on community, place, religion and other social relations. However, with the advent of the nation state beginning at the end of the Middle Ages and culminating in the nineteenth century, centralized identity systems have become the default. These centralized systems produce identifiers and properties about us at very large levels of aggregation, with typical systems retaining the primary identifying information covering millions of participants. States create and maintain registries for the area they have sovereignty over, recording who owns what land, who is born, married, or has died along with issuing licences and permits for various practices. The registries that they maintain provide a common source of truth for commerce and other systems to orient around and provide coherence. James Scott has done some of the best work on the functioning of states and these systems in Seeing Like a State. While the use of registries evolved over centuries, identity infrastructure as we know it is a recent phenomenon. The current systems for bootstrapping one’s identity from birth registration, so to later issue documents like Passports, emerged in the first half of the 20th century.
The state’s monopoly of registries does not mean complete control over identity. Citizens in common law countries have the right to call themselves whatever they want as long as they don’t use alternate names to commit fraud. People always participated in a variety of underground clubs, grey economies and marginal communities where people chose to use names other than those that appear on their official government issued documents. The internet created a panoply of contexts Yet, in the lives of most individuals the internet was the first institution to really dent this monopoly.
The internet created a proliferation of identifiers the patterns we have today are a patchwork made by private companies for very narrow domains for commerce and media applications, and later for business and productivity. This is arguably the beginning of decentralizing identity registries beyond governments.
However this quickly became problematic, as for each online service a user needed a unique account, meaning we each have dozens if not hundreds of different digital identities. The Identity Provider (IdP) became a “solution” to the issue of digital identity sprawl. This step back to centralization means people are required to leverage identifiers issued to them by Google and Facebook as the anchor for their identity and data across the digital world.
Kim Cameron has produced some of the canonical writings on the objectives and challenges of producing the internet’s missing identity metasystem. Among which is his Laws of Identity which propose a number of compacts all systems contacting user data should adhere to. Ultimately a number of guarantees he outlines are not compatible with centralized identity systems.
User Control and Consent with Justifiable parties
Any identity system depends on the trust a user bestows on the system. Crucially, these systems have a high bar pass in order to be viable. It needs to protect the user from deception by: identifying the people seeking the information, produce guarantees the system is storing user information in the right place, and make sure that this contract doesn’t change in different contexts (work, commerce, personal). In doing so an identity system must transparently show what parties are accessing the data, and justify why they have access to this.
Every identity service, must justify why it must be a party to the transaction, and for most cases this is not justifiable given the information leaks inherent in these architectures. Until recent advances in open standards, central providers such as Log-in With Facebook, and Microsoft Passport, were the only technical way of achieving single sign-on. Though in the latter case, the justification for using Passport across the internet was not credible to users, and failed to get widespread adoption. It’s perhaps telling that users tolerate Log-in With Facebook, and perhaps justify its access to data across the internet, given that Facebook already has such a large cache of user data.
To put the inadvertent information leak in stark relief, Aadhaar India’s centralized digital identity system is being used by private companies to power punch-clocks tracking workplace attendance. For the implementer of the attendance system, having a definitive unified identity provider is a boon, however the centralized design creates a surveillance apparatus, where every worker’s arrival and exit is logged by a government server, by the simple act of the authorization handshake. To put this example in the context of the Domains of Identity above, the government “registration” and “transaction” domains and employment “transaction” domain are connected on a daily basis.
The strongest justification for identity service intermediaries historically has been technological, that the state of the art for reliable high-throughput systems had been in private, closed source, hyperscale providers.
Pluralism of operators
Take for example our reliance on our phone number as a widely used account recovery pathway for various accounts that hold core identity and data. Gaining access to a phone number in the US, and porting to a new phone, is an exploit which happens routinely (and in the case of crypto assets, a common vector for being robbed of millions of dollars in a single transaction). But consider the case of someone unable to pay their phone bills. Their entire identity is tied to this particular identity provider – the phone company. Internet consumers are very well educated on the need to have account recovery mechanism (and data backups). But these both remain unsolved problems since identifiers, such as phone numbers, Facebook accounts, etc. are themselves controlled by a small number of corporate entities. To truly diffuse power and spread it across a wider range of operators would require identifiers themselves to rest with a wider range of individuals, groups, and entities in the network, rather than with a few central providers.
Part Two of this series discusses the applicability of decentralized identity. Part Three focuses on its transformative potential.