Intersectional Social Data
E. Glen Weyl, Kaliya Young (Identity Woman) and Lucas Geiger
October 24, 2019
In our previous three-part series, we motivated the case for decentralized identity systems, and exposed some of the current frameworks for implementing digital identity systems. In this piece we expose some of our collective research in Decentralized Identifiers (DID) and identity for emergent social structures. Finally we suggest further avenues of investigation and outcomes of the public goods of the internet post decentralized identity.
The Missing Layer
The open standards on which the internet is built is one of the most impressive global public goods ever created. Yet it was hardly “planned” as such, and certainly not for the uses that are made of it today. In his classic Internet Galaxy, legendary sociologist of technology Manuel Castells describes how the cultures of the military, academia and hackers/tinkers/creators collaborated to create it. This culture had an astonishing agility and commitment to building working systems that lent it staying power that systems developed in more commercial settings lacked. As a “network of networks”, it built on practices that participants actually used productively, rather than theoretical constructs engineered from the top down.
Yet for all its transformative benefits, this history left the internet with some critical holes. Because it developed in contexts where extremely high and institutionalized trust and identity systems lay in the background, the base layer had no focus on identity verification or other frameworks to establish trust among strangers. Thus, as Castells wrote, a fourth, commercial culture was layered onto the internet when it opened to such activity in 1995. It was at this time that people outside of technical communities gain access to accounts and e-mail addresses from commercial services like America OnLine.
The structural form of identity created by these commercial services has long been in tension with the basic spirit of the internet. It is a “networks of networks” based on open standards and decentralized communities. But without open standards for digital identity that echo the networks of networks form, the system that has emerged in the past two decades places tremendous power in the hands of a few large multinational corporate platforms that have now become “identity providers” for billions of people. Since this problem first became apparent in the early days of the internet, researchers have been working on designing identity protocols that better fit the spirit of the internet’s original designers.
Decentralized Identity State of the Art
In the last several years we have had some significant innovations to make a vision that affords greater agency to network participants a reality. Decentralized Identifiers aim to allow network participants to generate their own identifiers through open standards rather than relying on a trusted entity to “provide” an identifier, or identity. An important element of these framework is cryptography, which allows for establishing mutually trusted information in a “minimalist” way (without sharing unnecessary additional information), and the idea of data repositories (secured often partially by cryptography) in which individuals can collect data pertaining to them. This latter element is often called a Personal Cloud though it might be more accurate to term it a “digital journal”, as it need not rely on an implementation tied to existing cloud architectures.
The question naturally arises, however, of how precisely these tools can be used as an alternative to identities “provided” by institutions. After all, information simply asserted by an individual is of little value in achieving trust with a stranger; this is the whole reason for the problems mentioned above with the early internet. One natural approach is simply to allow individuals to more easily store and control, through DIDs, the credentials they are issued by institutions. Governments already issue birth certificates, drivers licences, and professional licences, insurance companies issue cards to those who bought insurance, banks issue cards to those who have accounts with them, schools issue student and staff credentials.
Identity for emergent social structures
Yet in many ways this effort is only the start of the attempt to create identity systems that truly capture the spirit of the internet. They may remove credentials from the control of a very small number of platforms, but they still rely heavily on existing and external social institutions that may be similarly concentrated, authoritarian or otherwise problematic. The great hope of information technology is that it might allow new paths of trust to emerge from the network of social relationships, rather than simply representing those that pre-exist the system. This would allow a digital infrastructure to augment and perhaps eventually replace institutions like governments and banks rather than just expanding the set of issuers of digital identity to include pre-digital power centers. We explored the transformative promise of such a world our previous series of blog posts. In this post we outline a potential formal framework for developing a system that could underlie it.
In her book A Simpler Way, author Meg Wheatly outlines three conditions for self-organizing:
- Identity — the sense-making capacity of the organization
- Information — the medium of the organization
- Relationships — the pathways of organization.
Core to any solution to developing any effective system of self-organized identity will be formalizing these concepts in some way. We discuss a framework for doing so in what follows.
Intersectional Social Identity
Intersectional Social Data (ISD henceforth) sees individual human identity is an evolving-over-time data set pertaining to that individual and that nearly all such data also pertain to or at least are known by other individuals with whom she interacts or has a relationship, others who we may say are connected to her in her “knowledge network”. This paradigm for data storage, control, identity and verification described in a recent paper that one of us co-authored, though many ideas and even implementations of aspects predate that work, and thus many readers will see echoes of ideas here in many other projects.
ISD tries to use this pattern of “natural” information sharing, together with “natural” networks of relationships, to substitute a rich and diverse set of social sharing and connections for the highly concentrated patterns of sharing and credit associated with centralized platforms.
ISD has three central primitives.
- First, each participant has a digital journal listing all her or his identifying information. Only that individual has access to the complete set of information in that store.
- Second, each participant stores, for each datum in her digital journal, the set of other participants who also store copies/mirrors of that datum (we will call this the “knowledge graph”).
- Third, each participant stores a degree of credit she is willing to offer every other participant (as well as temporary “liens” on such credit, though we will only briefly discuss his feature below); we will call this the “credit graph”, drawing on work on using such a graph to support “social collateral” for lending. Here credit is meant to evoke the senses of giving credence to a statement (“I credit that account of events”), lending (“I am willing to offer you credit”) and a form of money (“you have seven credits”). Ultimately, however, it is simply a formalism primitive to the system we describe and we always use this word below to refer to this formal object. In many models similar to those we discuss here, the word “trust” is used instead of “credit”.
An illustrative example would be location data as recorded by a smartphone. Suppose your smartphone locally and very securely recorded all your location data over time (a nice example due to Jeff Jonas) and also for every person you saw and where there was mutual consent recorded a link confirming your co-location at that time (say, for anyone in line-of-sight). Then your digital journal would be your phone full of your path through space-time and the knowledge graph is the list of people you were co-located with at these points in time. Finally, for every person you know and trust you would record a numerical credit score, roughly corresponding to the amount of money you would be willing to lend that person. This information would be populated by a mixture of user input and algorithmic completion. While we will use this example repeatedly below, we should be clear that we do not intend it to constitute the only or primary data stored in ISD structures, simply one that is simple to visualize. Much other information, about qualifications, communications, etc. could be carried on an ISD substrate and in many examples below might be more natural to convey.
Readers will inevitably have some questions about this illustration, but we will use it to highlight some of the basic functionality that it could allow, if it could be made to work:
Verifying an attribute of a participant:
Suppose that Malik meets B and wants to prove to B something about himself, such as his location last weekend, perhaps because he made a commitment to them to be in a particular place. Malik could send a message to all his connections who were with him at the time (or, in practice, their phones would communicate) and produce an encrypted (by Malik, B and those who were with Malik, against the surveillance of anyone else along the chain of communication) version of Malik’s claim to B about his location. Let’s call the encrypted version of this claim “Claim Alpha”. Upon this production, Malik’s witnesses and B both send out messages in their networks seeking paths of trust between Malik and these friends.
The simplest case would be when B directly “credits” (has assigned a high credit score in) Malik; in this case, no verification is needed. This represents the case implicitly assumed in much of the early internet, where networks were among close communities. The next simplest case would be when B credits one of Malik’s witnesses. In this case, immediately upon sending a message to their credited contacts, B would find that one of them was attesting to Claim Alpha. Note that because Malik has several witnesses, even if B credits each of Malik’s witnesses individually no more than B credits Malik, they (B) may be able to achieve a greater total credit based on the independent willingness of all these credited individuals to vouch for Claim Alpha.
More elaborate examples simply iterate this process. B may ping all their credited contacts looking for someone attesting to Claim Alpha and find no one, or only people with insufficient trust. They would then ask all these credited contacts to ping theirs, and so forth. Simultaneously Malik’s witnesses, failing to encounter directly someone looking for Claim Alpha to be verified, would ping those who trust them, asking them to attest to Claim Alpha based on their trust of that witness, and so on. A long line of network sociology literature suggests that all humans on the planet are connected by a relatively small number of degrees of social separation (4-6). Separations are likely to be even less within most realistic settings where verification is required. This should allow the process of seeking paths to terminate relatively quickly, though the details of the protocol would differ based on the precise algorithms used.
Furthermore, for most such connections, once we reach to several layers out, many paths are possible. While the total amount of credit that can “flow” along any given path is limited by the weakest trust link along that path, much greater credit is likely possible based on simultaneously engaging multiple paths. Searching for the maximum credit that can be routed between two points is equivalent to the canonical computer science problem of “maximum flow”, as analyzed in a recent paper. Precisely the balance a system would strike between terminating quickly and thus seeking short paths and finding the global maximum flow would depend on the application at hand and how much credit (or more informally trust) is required for it.
A common use of the above approach will be for proving a participant’s right to access some resource, a function often called “authorization”. The higher stakes If the authorization is, for example, to view a critical national secret, a very extensive search might be used (as is usually used to in real life to allow access to such sensitive information). If authorization is simply to send a message, we might focus on short paths as these would generate enough credit.
Liens on used credit (“system integrity”):
To prevent bad actors in this system from abusing the credit offered them, there must be some way to penalize abusers and ensure future abuse is impossible. The credit architecture offers an extremely natural and completely decentralized way to do this. B, upon accepting a claim through the process above, would put a temporary “hold” or “lien” on the credit they put in all their direct connections used to establish credit in the verification process. This lien would ensure, for example, that credit could not be “double spent” on two different claims before it was “repaid” by B becoming confident that the claim turned out to be true. As time went on and no problem with the claim was found, credit would gradually recover and the lien would be removed. Eventually credit would be repaid with interest, as a correct verification engenders not just the return of credit but its increase.
In the case that trust is betrayed (the statement turns out to be false and thus not “creditable”), the relevant quantity of credit would be destroyed in that relationship. If the connection to B were indirect (that the path was longer than a single link), B’s direct connections would obviously be aggrieved that they had their credit destroyed because they vouched for claim that turned out to be false. They would thus in turn burn the liens they had placed on their credit relationships, and so on down the line. Note this could all occur purely locally/bilaterally, without any need for a global view of the trust relationships. Each burning of credit would set off another without the identities of participants down the chain being revealed to others in the chain. The same would go for appreciation of credit. This implies no need for global policies about credit disputes or resolution of such disputes. Each participant could set their own policy, perhaps have it be systematized by an algorithm and simply communicate this to their contacts, though obviously some defaults would likely be common or emerge from the system. There might be bilateral agreements between network participants to adjust trust in both directions as a sort of “trade”.
Verifying unique humanity of a participant (“sybil-resistance”):
Suppose now that Yahsin wants to administer a democratic, one-person-one-vote election and wishes to ensure that every participant in this election is a human and is not redundant in the data set. Fernanda registers to participate in the election, though Yahsin only knows that some node (call it “Node F”) is requesting permission to participate. Yahsin is happy to allow any human being to participate in her election once, but wants to ensure that this node is not simply controlled by another human already registered.
To do this, Yahsin asks Node F to report and verify, using the above procedure, her location at, say, 50 of 70 randomly chosen points in the past decade. On the one hand, the chance that Fernanda’s journal has recorded and that she can get these locations verified is very high and the probability that anyone else other than her registered for the election was in precisely the same place at each of these time is vanishingly small. On the other hand, revealing these 50 points out of Fernanda’s space time path tells Yahsin almost nothing about Fernanda, especially given that she doesn’t even learn her name, home address, etc.
Thus, by asking each participant to register with answers to a “random” collection of questions, bot/sybil attacks can be deterred and yet almost no relevant privacy broken or identity disclosed. Furthermore, Fernanda can ensure that Yahsin is not secretly trying to hack her identity by comparing the allegedly random questions Yahsin asks against other questions she has been asked in the past or that other institutions plan to ask in the future and either refuse to answer or strategically choose 50 less revealing points.
Logging into a device (“authentication”):
ISD might offer an interesting, but highly speculative and future-looking, alternative to standard password, key or biometrics-based login procedures. Let’s focus on the login to the Digital Journal itself, as it should be clear this could hold authenticating information and/or Private Keys associated with Peer DIDs for other services and thus is the critical point of failure that would need to be rigorously secured and where most of the value from authentication for the user would lie.
The idea is to use the information stored in the Digital Journal (and redundantly, though imperfectly due to memory, in the brain of the individual) as a basis for a key recovery process based on queries and responses about identity information pertaining to the individual. That is, rather than an artificial password (which can be stolen) or biometrics which are not secret (so they can be “copied” – existing templates may also be hacked from databases) providing the primary basis for authentication, the full personal identity profile internalized by the user acts as the authentication substrate. The more sensitive and more extensive information the user tries to access in the Digital Journal, the more questions and harder questions are asked. The protocol could be designed to adapt to the memory of the user on set up and updated for changes in her cognitive capacity so that authentication can happen fairly quickly and with high probability successfully for the true user but will lock (or become much harder to access) for a fake user. Obviously memories of agents will differ over time and the lifecycle, as well as with medical conditions, and thus algorithms would have to be designed thoughtfully to adapt to the different abilities of different users (e.g. length v. precision of memory).
Perhaps the most interesting feature of ISD in this context is that because of the social nature of the relevant data. The current way that social recovery has been envisioned means the “individual” ask their friends to help them to recover their keys by returning to them chards of a recovery key. It has been shown by researchers that type of social recovery is vulnerable to social engineering attacks. We are proposing a way to do social recovery that because of the networked nature of ISD would be less vulnerable to this type of attack. An individual attempting to log into the journal may, perhaps with some partial help from the journal, contact others who share the relevant datum. If she can persuade this other user that she is legitimate, the other user may share the datum with her, allowing her to proceed on authentication. This converts the simplest version of social recovery into a fluid process where a combination of memory of personal identity and social reconstruction of that identity, much as in everyday life it maintains a sense of self, helps maintain authentication.
While highly speculative and differentiated from existing authentication systems, there is something so deeply intuitive about this system that it shows up in popular culture. For example, in the most recent (6th) season of the popular television show Agents of Shield, a team is trying to identify which of their bodies may have been “possessed” by an enemy that cannot access their memories during possession. They use procedure almost identical to the one above, with repeated telling of socially partially known secrets and social vouching for those secrets, to determine who is reliable. It is precisely the extension of these intuitive IRL authentication procedures into our digital lives that we hope future iterations of ISD will aim for, even if this particular protocol proves unworkable.
Alongside these fundamental functions, ISD has several interesting properties that interweave with its basic functionality:
Overlapping, partially common agency:
A central feature of ISD, which differs from the current predominant thinking around how Verifiable Credentials will work within Decentralized Identity or Self-Sovereign Identity frameworks, is that the credible revelation of each claim or datum to other parties is always at least partially under the control of a group of users who can verify its validity. While anyone with access to a datum may try to disclose it, she will struggle to do so without the consent of at least some of the others who also have agency over it. She will not be credible except to those who directly trust her without a validator. This will make it likely that she will need to at least alert and likely have the support for disclosure of others who share this datum to credibly disclose it. The greater degree of credit she wants this datum to receive, the more others she will have to alert and get the support of. This would allow a community sharing a datum to enforce standards of non-disclosure if it held these collectively, while threats to burn trust relationships may help enforce collective decisions to disclose. In short, while the exact details will depend on community standards, it is the community associated to each datum, rather than any individual it pertains to, that will effectively have sovereignty over it, helping address concerns about the networked nature of disclosure and privacy harms raised by thinkers like danah boyd.
This contrasts to much of the thinking within the current Decentralized or Self-Sovereign Identity framework where the validity of facts is established by “verified credentials” being issued by authorities and then being held under the full discretion of the individual to whom their are issued. That system is based on a notion of complete individual independence enabled by external “institutions” empowered to create this independence. ISD, on the other hand, has no asymmetry between issuers of credentials and “individuals” who receive these; instead, participant holds and helps validate data that collectively pertain to them. However, ISD can naturally be consistent with and even powered by some DID frameworks, especially those based on pairwise connection keys.
Necessity of democratic consultation:
Like the above point, the decentralized but social nature of data sovereignty will have a tendency to spread power in information structures that are currently consolidating into surveillance states and surveillance capitalism. In contrast to current data architectures, data will be held diffusely in a range of communities. To conduct an investigation or put together a pattern of facts, a centralized authority will need to contact at least one member of each of several communities of knowledge and to have great confidence will have to contact many members of each. Following our earlier location example, while at present there is likely some platform that has access to the location of a suspect of a crime at all times, in an ISD setting the best way to ascertain this will be to look for people who were co-located with this suspect at different moments, a digital version of the pre-digital publication of the face of someone accused of a crime and request for information leading to that person’s arrest. For more confidential investigations, making inquiries in different communities about that person. This will not precisely create a majoritarian democratic check, as each member of the community could choose or be induced by the authority to stay quiet about this request for information. Yet the necessity of seeking reasonably broad permission, and the fact that anyone asked to provide information will know others are being asked as well, will create some accountability for surveillance and investigations that are truly inappropriate.
This will tend to create not just awareness among but the potential for collective action by a variety of consulted parties, tending to ensure a data structure that upholds “polyarchy” both in the political science sense of the rule of the many due to Robert Dahl and in the sense the term is used in the user-centric identity community of replacing a single global hierarchy with many intersecting ones at different scales. In both sense the term is closely related to the pluralistic values core to many societies. Without technical architectures of this sort, fundamental protections on civil liberties, such as Fourth Amendment protections against unreasonable surveillance, will become increasingly hard to even define.
Partial identification:
Current digital architectures too often force a choice between anonymity or pseudonymity (with aliases linked to no past behavior, and with an unlimited right to create new aliases) on the one hand and requirements for people to share their real name as presented on formal identity documents issued to them by states that they have a established a relationship with.
Limited Liability Persona (Ref1) (Ref2) were put forward within the community of practice focused on digital identity over 10 years ago by Bob Blakley and Mike Neuenschwander, who at the time worked for Burton Group (a specialist analyst firm focused on identity that was absorbed by Gartner). One of the co-authors of this piece came up with the Spectrum of Identity to express the range between super strong verification of ID and total per-post anonymity.
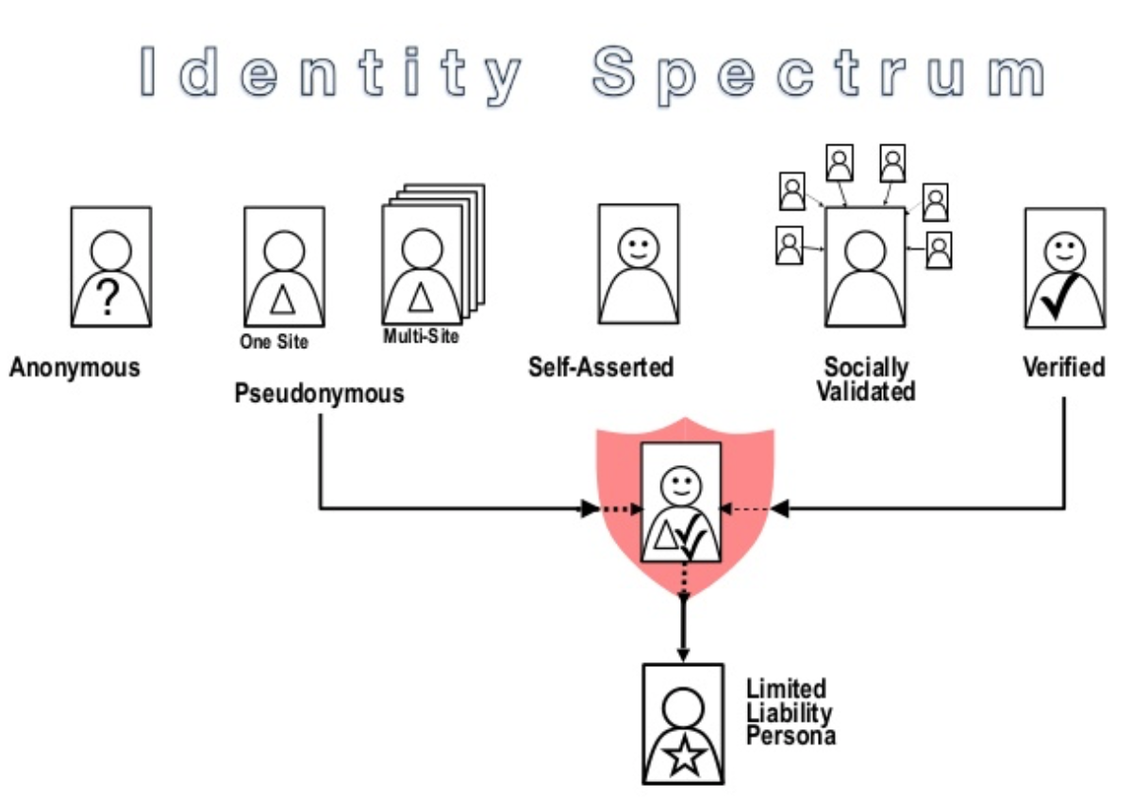
In this model some type of entity a corporation, a nonprofit group or potentially some type of quasi-government agency or role like a judge creates a link between the pseudonym and the “real world identity” and gives the limited liability persona the power to act and interact without revealing their real identity but if the persona mis-behaves in some egregious way can be held accountable.
ISD offers both an interesting basis for achieving and some potentially valuable extensions to the functionality of this intermediate position, bringing identity systems one step closer to the functionality of identity in thick social settings. In particular, an enrolling participant could prove to a system certain properties of themself, while omitting others, known as selective disclosure. In some contexts, features relating to romantic historic and gender identity might be relevant; in others, professional credentials; in yet other national origin; etc. All this could be proved to the system without requiring the standard litany of name, address, government ID numbers, email, etc. that enrollment typically requires.
Of course, present centralized identification schemes also only reveal partial identifying information; the above “standard” identifiers are a very thin representation of an individual’s identity. The trouble is that so many of these identifiers are consistent across contexts, correlatable and quasi-public. One’s real name and birthdate create a defacto correlatable identifier across many contexts. This means that it is often possible to use these to reveal the rest of the enrollees identity through dataset completion/matching, exposing an important security vulnerability that leads individuals to often legitimately prefer anonymity or pseudonymity. Systems that allow these, however, easily become prey to manipulative actors that abuse anonymity and pseudonymity to create many fake accounts to propagate their domination of privileges (such as voice and votes) that are reserved for unique humans with various traits. ISD could resolve this problem while at the same time offering more useful identifying information than present regimes, given that name, birthdate, social security number etc. are often not very relevant to the service at hand compared with e.g. elements of work experience or medical history. The medical domain seems particularly relevant, as patients may wish to share important medical information without identifying themselves beyond this information.
Credit, not probability, scores:
Another interesting element of ISD, which contrasts with other schemes, is the way it yields scores for imperfectly reliable verification (that is, all verifications, as nothing can be 100% relied upon). A natural way to do this would be a probability score, the chance that a claim is correct. Certainly, ISD might support this sort of function, by allowing those vouching for a claim to assess a less than 100% chance of its validity. Yet the central feature of ISD is to provide a quite different kind of a confidence score
A probability is an external object, independent of how much faith one places in it. A probability should stay the same whether one bets $100 or $1,000,000 on the event it is the probability of. This is not true for claims verified over a network like ISD, however. If one uses any identity system to hand out very large amounts of money or other value to participants based on claims, there will be an enormous incentive to abuse credit to extort this value. On the other hand, there will be little incentive to cheat for small rewards and thus it is unlikely verifications will be false. Unlike probability, which is based on an objective and non-adversarial process, credit in an ISD network is based on the maximum value one can convey before the system is likely to break. Such credit is much more useful in many applications as the demanded credit can be more easily matched to the stakes of what value is being allocated using that credit and thus credit offers a helpful metric of how much value a system or network can support the exchange of.
Inalienability of identity:
Another interesting element of ISD, though highly speculative as it relies on the authentication functionality we discussed above, is its potentially high degree of security it could afford for the most sensitive contents of a Digital Journal. Passwords and keys, as well as any small list of personal information or even social contacts can be relatively quickly disclosed under coercion or duress, and biometrics stolen based on a brief period of coercive control or theft. A progressive authentication approach as described above, which randomly employs different identifying information at different moments, on the other hand, would make it nearly impossible to “unlock” and thus access all contents of a Digital Journal without having access over the full period of time to the attacked individual and the ability to spoof her social contacts.
Of course, such access and coercion are possible, just as slavery occurs with disturbing frequency in the modern world. There are limits to what any digital system can guarantee without decent real-world institutions to prevent property in persons. However, we would ideally like a system that is what we might call “secure-up-to-slavery”: identity can only be broken or sold under conditions equivalent to an individual being taken into or sold into slavery. Such a guarantee makes it unlikely that the abhorrent prospect of a robust individualistic market in digital identities could emerge. Such a market would, if feasible, undermine the whole purpose of identity systems discussed in our previous posts, as it would make identities equivalent to a financial value. ISD, if authentication based on it proves feasible, seems to offer hope of achieving security-up-to-slavery against sale and coercion.
Non-individualistic identity:
Finally, and most ambitiously, ISD offers the possibility of going beyond the traditional, individualistic foci of most identity systems to a richer social understanding that could enable fundamentally different functionality than the most perfect individual identity system. In particular, the social context allowed by ISD may be critical for certain applications, above and beyond the way it enables individual identification. As we discussed in the third part of our motivating post, for applications such as creating data collectives or minimizing the ill effects of collusion in Quadratic Finance/Liberal Radicalism (QF), simply identifying separate human individuals is insufficient; we need to know more about the social structure in which trust and identity operates. ISD seems particularly well-suited for this. For example, its capturing of the social structure of data sharing is a natural substrate for forming meaningful Mediators of Individual Data, especially given our point above regarding common sovereignty over data.
Let’s continue into this point focusing on the case of QF, a system of matching funds for private contributions to public goods based on the principle of matching more contributions to popular projects and matching more smaller contributions, both to overcome standard free-rider problems. Obviously, such a system relies on a notion of separate individual identities but implementing it in the context of ISD would naturally lead to something beyond this.
Because any verification of separate identity in ISD will have bounded trust associated with it, and the degree of trust will depend on the number and depth of paths explored to ensure this trust, it will be natural for an authority administering QF to limit the additional matching funds that can be allocated to an individual to the trust in her verified identity. Yet by the structure of QF, marginal matching funds are not simply a property of an individual, but of groups of individuals, and those participating in any given QF funding exercise may be socially related and thus may put strain on the same set of trust links. An administrator would thus natural wish to limit not simply the matching funds allocated to each individual to the trust in her verified identity, but also to sub-groups based on the aggregate trust associated with them.
Such a dynamic would tend to allow groups accessing a system through independent trust pathways to receive much greater matching funds than groups all passing through a single or small number of credit “bottlenecks”. From a security perspective, this would be helpful in deterring bot attacks. Yet from a deeper point of view, such a flexible, group-based account of identity and participation could transform our perspective on identity and identity-systems. Many philosophers and sociologists have emphasized the importance of conceiving social problems in non-individualistic terms.
For example, philosopher Danielle Allen sets up the fundamental mechanism design problem not as reconciling individual selfishness with the common good, but instead reconciling the diversity of social formations and commitments with the need to cooperate and share this earth, a principle she calls “difference without domination”. Such perspectives emphasize the importance of especially subsidizing “bridging ties” across social groups, ties that would naturally be subsidized under such arrangements.
Precise formalization if how such limits could be implemented, especially without creating incentives for suppressing social connections, is an important direction for future research, some of which is on-going.
ISD also admits different interpretations, some more ambitious or “maximalist” than others.
A modest proposal would be to introduce ISD into existing workflows of emerging DID systems. In this mode ISD is an optional protocol for claims signing and validation within emerging decentralized identity frameworks. To date DID systems, such as Sovrin, will rely on claims from central credential authorities (e.g. British Columbia Business Registrations), which can be stored and verified without interaction with the credential authorities. Or simply, centralized claims with decentralized usage. We can imagine ISD as enabling decentralized claims production coupled with decentralized usage.
Taking this further, beyond a protocol the data structure itself is of general applicability. Much in the same way that a blockchain data structure is generally useful writing immutable data and verifying inclusion, one could view ISD as a general purpose data structure (or more technically an abstract data type), to be leveraged at many steps in the identity workflow. ISD maximalists could imagine theoretically authentication of a user accessing a system be done by querying that user’s graph (assuming that propagating the query through the network can be done with sufficient efficiency).
This more ambitious proposal, using authentication neatly illustrates how something we assume to be trivial, logging into the system depends largely on the assumption of static identity truths. One “solution” blockchain identity systems propose to solve is that of the internet’s missing “truth” function (which hyperscale centralized platforms provide). A number of blockchain identity services, aim to supplant the centralized platforms. But this may be a missed opportunity. Conceiving of ISD as a data structure based on a fundamentally different conception where most truth is social, but local to sub-communities on a network. While it may seem foreign and impractical at the moment, such a local social epistemology is central to much modern social theory, especially the “agonistic pluralism” of Chantal Mouffe who emphasizes the necessity to find systems for cooperation absent deep shared or objective truths.
In either case, much is missing from the sketch above and from the research on ISD so far; it is more of a proposed paradigm than a detailed solution. To take just one example, while copies of data are shared in the network, there are different data that are imperfectly informative about each other that are not described as linked above (e.g. the weather in my town and the neighboring town). How should relationships among these be represented? We look forward to much more research on this and many other topics that can explore and further articulate the potential and limitations of the ISD paradigm.
Post Cloud
Many workers in the emerging space of “re-decentralization” of the internet, are motivated by some secular trends in computer science and cryptography that are creating new paradigms for online applications. We are beginning to see sketches of the post-cloud world, so called Web3, where applications can be provided without the need for central data platforms. In this Web3 paradigm, decentralized infrastructures, gain new importance. The routing, storage, execution of the computer programs happen effectively in a public-goods ether, autonomous systems of blockchains, IPFS, CRDT. In these autonomous systems identity gains a central role, not just for the convenience of the user, but existentially for these new networks and application frameworks. Governance of these public goods, while preserving their open and robust, characteristics, is a particularly wicked category of problem, before excluding the use of identity systems. For that we refer you to Vitalik Buterin’s excellent On Collusion.
Which brings us full circle. In the internet’s early days there was arguably no such technology which could power a decentralized identity system. And perhaps if it had been done, we would have also achieved a decentralized governance scheme for the internet itself, whereas today we rely on hyperscale platform and the “autonomous systems” they produce to manage the lives of the thereby atomized individuals participating on these networks. To achieve truly decentralized, dynamic, adaptive, emergent and responsive governance and a pluralistic humanistic vision for the future of technology, it will be critical to scale up open social identity schemes and data architectures like those we discuss here. The coming years will tell whether ISD in particular can play a productive role in that process and what alternatives emerge.